
Weather Tweets Sentiment Analysis
A project which features a task of classifying user's sentiments through tweets related to weather.
A data enthusiast by day.
A sport fanatic by night.

I have been interested to do a classification-type project related to healthcare and illnesses. I stumbled upon this dataset on kaggle and felt there was great potential to develop an algorithm to predict a person having diabetes. Besides finding an appropriate classification algorithm, it would be useful to identify relevant variables to explain a person having diabetes.
Firstly, I would be conducting some basic exploratory data analysis to visualize some of the data present. Next, I would normalize the data due to there being a mixture of continuous and categorical variables. After which, I would be able to train several models using machine learning algorithms I have experience with.
The measure of accuracy used was f1-score which makes use of precision and recall. In a topic such as disease prediction, I believe that False Negatives (wrongly predicting a person being free from diabetes) is highly critical. Thus, the highest f1-score is considered the best as it would maximise the percentage of accurate positive predictions.
Now that the data has been prepared, I proceeded to develop models using 4 different algorithms : Logistic Regression, K-Nearest Neighbors (KNN), Decision Trees & Random Forest. The most accurate algorithm was the Random Forest algorithm. Here is a summary of all approaches:
| Method | f1-score |
|---|---|
| Logistic Regression | 0.923077 |
| KNN (no tuning) | 0.942623 |
| KNN (with tuning) | 0.945607 |
| Decision Trees | 0.959677 |
| Random Forest | 0.968254 |
Additionally, you can view the detailed jupyter notebook for the best performing model here.
Now that we have the best performing algorithm, we can move on to finding important variables or features in predicting a person having diabetes. The following plot was obtained by extracting feature importance from the best performing Random Forest model.
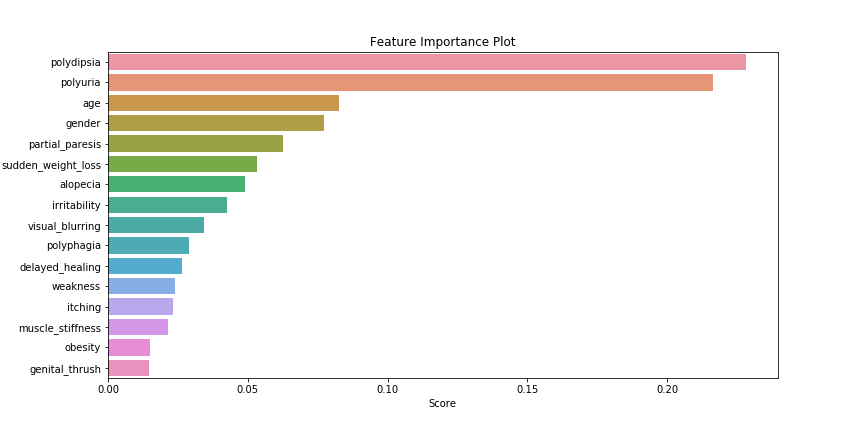
As seen above, 2 of the most important variables appear to be Polydispia and Polyuria. Polydispia is a medical term for experiencing extreme thirst while Polyuria is a condition where a person has excessive urination. Cross-referencing this with online sources, I found that these are indeed 2 conditions which are found to be early indications of a person having diabetes. Thus, its high importance in our Random Forest model is justified.
Some of the work done as school projects and on my own time to put into practice some of the technical knowledge gained.
A project which features a task of classifying user's sentiments through tweets related to weather.

A self-initiated project to create an interactive dashboard to visualize the population of motor vehicle users in Singapore from the year 2005.